
Ученые разработали наушники с алгоритмом на основе искусственного интеллекта (ИИ), с помощью которых пользователи могут выбирать конкретные виды звуков и управлять ими

Наушники. Фото: freepik.com
Авторами устройства стали исследователи из Вашингтонского университета. Они создали систему глубокого обучения, встроенную в наушники, которую назвали «семантическим слухом».
Она умеет убирать весь шум фона, передавая записанный звук на подключенный смартфон. Алгоритм сейчас различает около 20 видов звуков, которые пользователи могут усилить или выключить с помощью голосовых команд или приложения для смартфона. Среди них сирены, детские крики, речь, звуки пылесоса, щебетание птиц, голоса животных и прочее. После настроек наушники будут обрабатывать только выбранные звуки.
«Понимание того, как звучит птица, и выделение ее из всех других звуков в окружающей среде требует интеллекта в реальном времени, чего не могут достичь современные наушники с шумоподавлением. Проблема в том, что звуки, которые слышат пользователи наушников, должны синхронизироваться с их визуальными ощущениями. Поэтому нужно обрабатывать звуки менее чем за сотую долю секунды», — пояснил старший автор опубликованной научной статьи Шьям Голлакота, профессор Вашингтонского университета.
Читайте также: Созданы очки, которые позволят незрячим «видеть» с помощью звуков
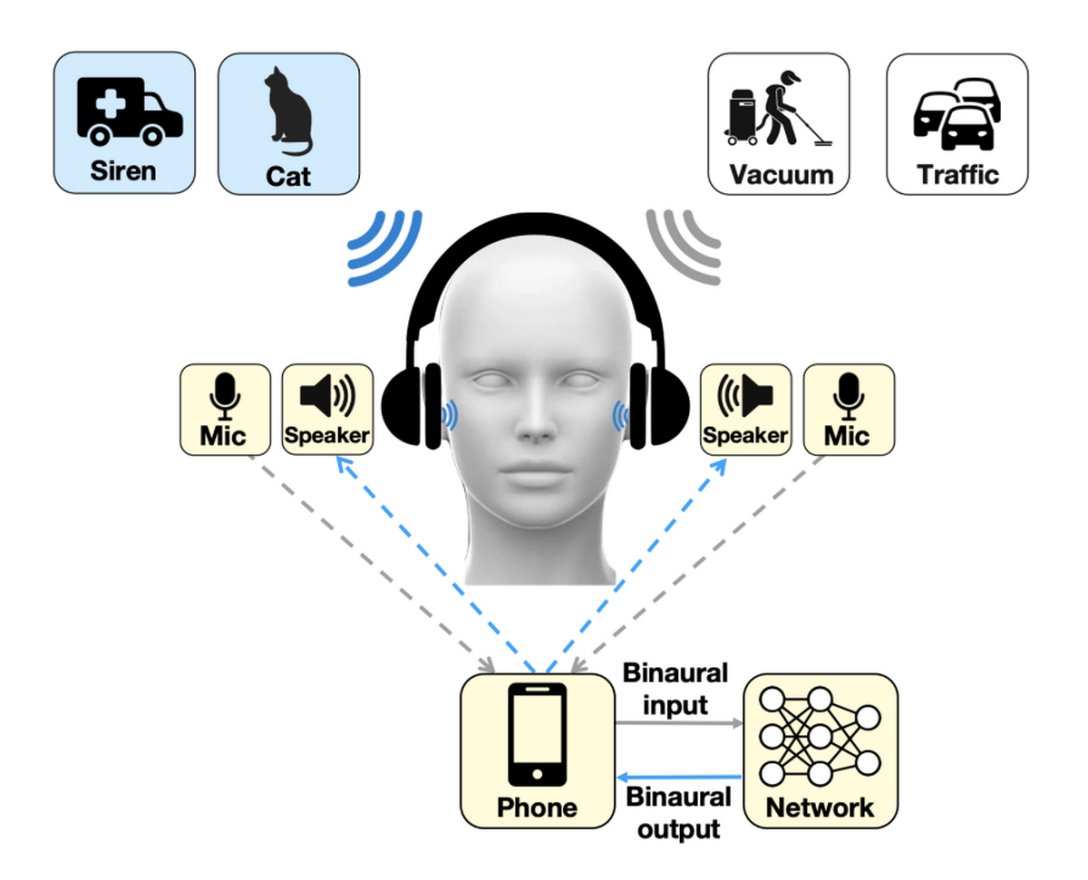
Фото: dl.acm.org
Из-за ограничений во времени вместо использования более надежных облачных серверов система «семантического слуха» выбирает процесс, основанный на шумах, передаваемых через смартфон. При этом, чтобы люди могли продолжать эффективно воспринимать звуки окружающей среды, система должна поддерживать эти задержки и другие пространственные сигналы. Поскольку звуки, исходящие из разных направлений, достигают ушей людей за разное время.
Ученые проводили эксперименты в различных условиях, в том числе на улице, в парках и офисах. Результаты показали, что наушники с ИИ могут изолировать целевые звуки (например, сирены) и одновременно устранять фоновый шум. Что касается вывода желаемых звуков, то 22 участника оценили его выше, чем исходные шумовые записи.
В то же время у системы иногда были проблемы с распознаванием звуков, которые показались ей очень похожими. Например, человеческая речь и вокальная музыка. Сейчас разработчики пытаются решить эту проблему. По их словам, «семантический слух» показал бы гораздо лучшие результаты, если бы ее модели машинного обучения ИИ получили больше реальных данных.
Ранее мы сообщали, что ученые из Дьюкского университета разработали имплант для мозга, с помощью которого можно общаться только на основе мыслей. Устройство должно помочь людям, которые страдают речевыми расстройствами или неспособны на вербальное общение по тем или иным причинам.
Ознакомьтесь с другими популярными материалами:
Google Chrome добавляет функцию чтения веб-страницы вслух
Alibaba запустила модели ИИ, которые понимают визуальный контент
Lenovo представляет потребительские AR-очки, которые можно привязать к iPhone
Источник: Interesting Engineering






